论文任务
Few-shot的多模态问题(such as captioning, visual dialogue, classification, or visual question answering)。 Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research.
现有方法用多模态预训练,再用“大数据”finetune到下游任务。尽管contrastive VL预训练具备了zero-shot能力而无需finetune,但只能处理classification,缺乏language generation能力(captioning或VQA)。 visually conditioned language generation在low data情形下性能不好。本文提出的Flamingo在open-ended VL任务中,只需要少量样本promote。

关键假设
大规模生成式LM是few-shot learners,本文认为这也适用于Vision Language任务,与LM的区别是模型需要能同时接受图文多模态交错的输入。
Large-scale generative language models (LMs) are good few-shot learners. A single large LM can indeed achieve strong performance on many tasks using only its text interface: a few examples of a task are provided to the model as a prompt, along with a query input, and the model generates a continuation to produce a predicted output for the task on that query. In principle, the same can be done for many image and video understanding tasks such as classification, captioning, or question-answering: these can be cast as text prediction problems with visual input conditioning. The difference from a LM is that the model must be able to ingest a multimodal prompt containing both image and/or videos interleaved with text.
挑战与方案
1. Unifying strong single-modal models. 单模模型本身不知道如何利用其他模态输入,引入其他模态输入的关键是要完整保留预训练模型的语言理解和生成能力避免不稳定。交错cross-attention和self-attention,冻结self-attention;gating mechanism。
2. Supporting both images and videos. 2D prior适用于vision但不适合language。使用Perceiver- based结构生成一组固定数量的visual token。
3. Obtaining heterogeneous training data to induce good generalist capabilities. 多模态数据集,直接从网页爬取会有图文弱匹配问题,比如CLIP。本文结合了web数据、标准的paired image/text和video/text数据集。
Contributions
1. Flamingo VLM模型,能够处理多种few-shot多模态任务:
○ 接受图文混合输入,开放式输出文本;
○ 架构+训练策略,利用大规模预训练的单模态模型。 preserving the benefits of these initial models while efficiently fusing the modalities.
○ 任意大小的visual inputs,适用于image&video.
2. 定量分析了Flamingo在各种任务的few-shot学习。 We reserve a large set of held-out benchmarks which have not been used for validation of any design decisions or hyperparameters of the approach.
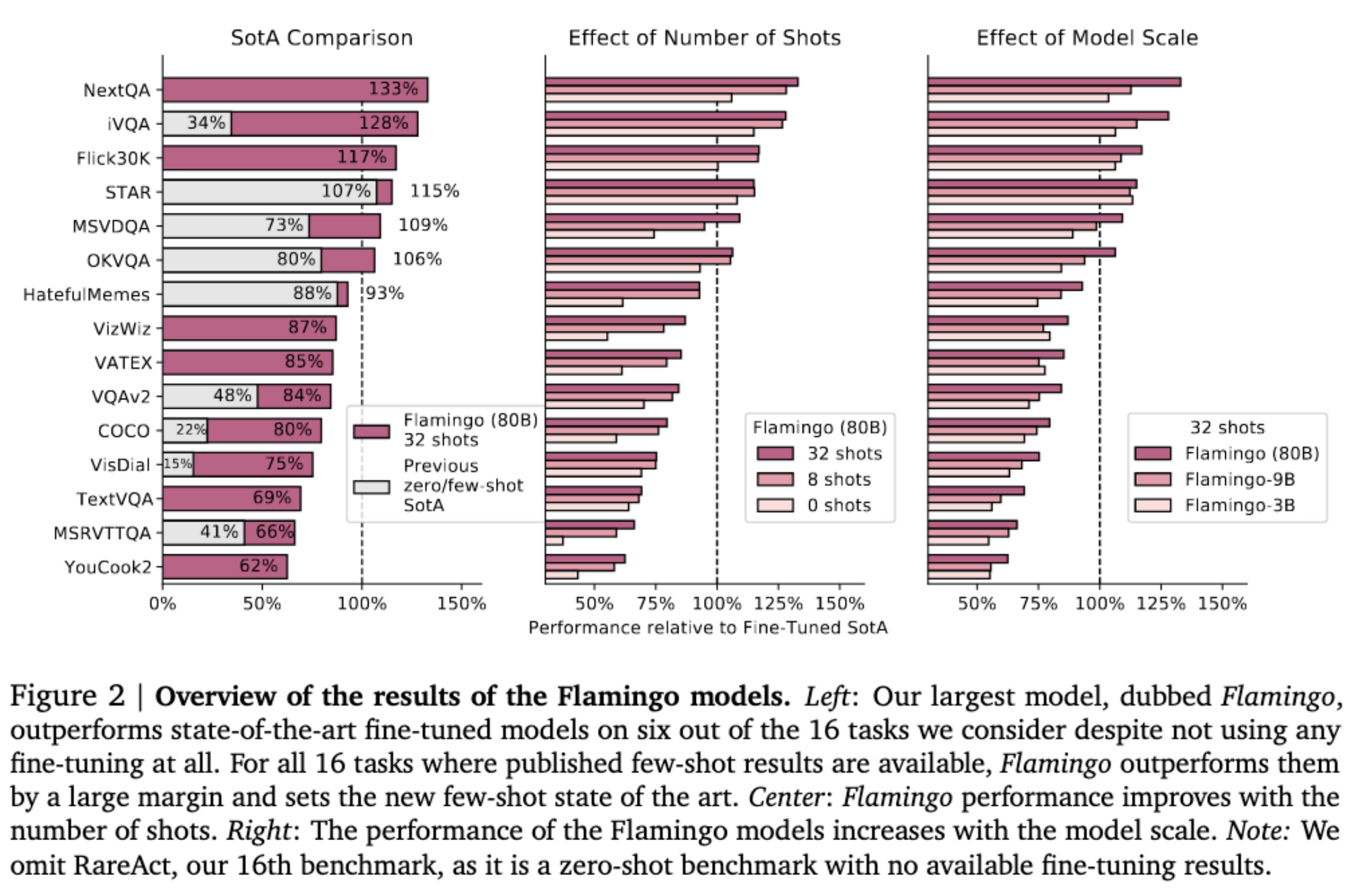
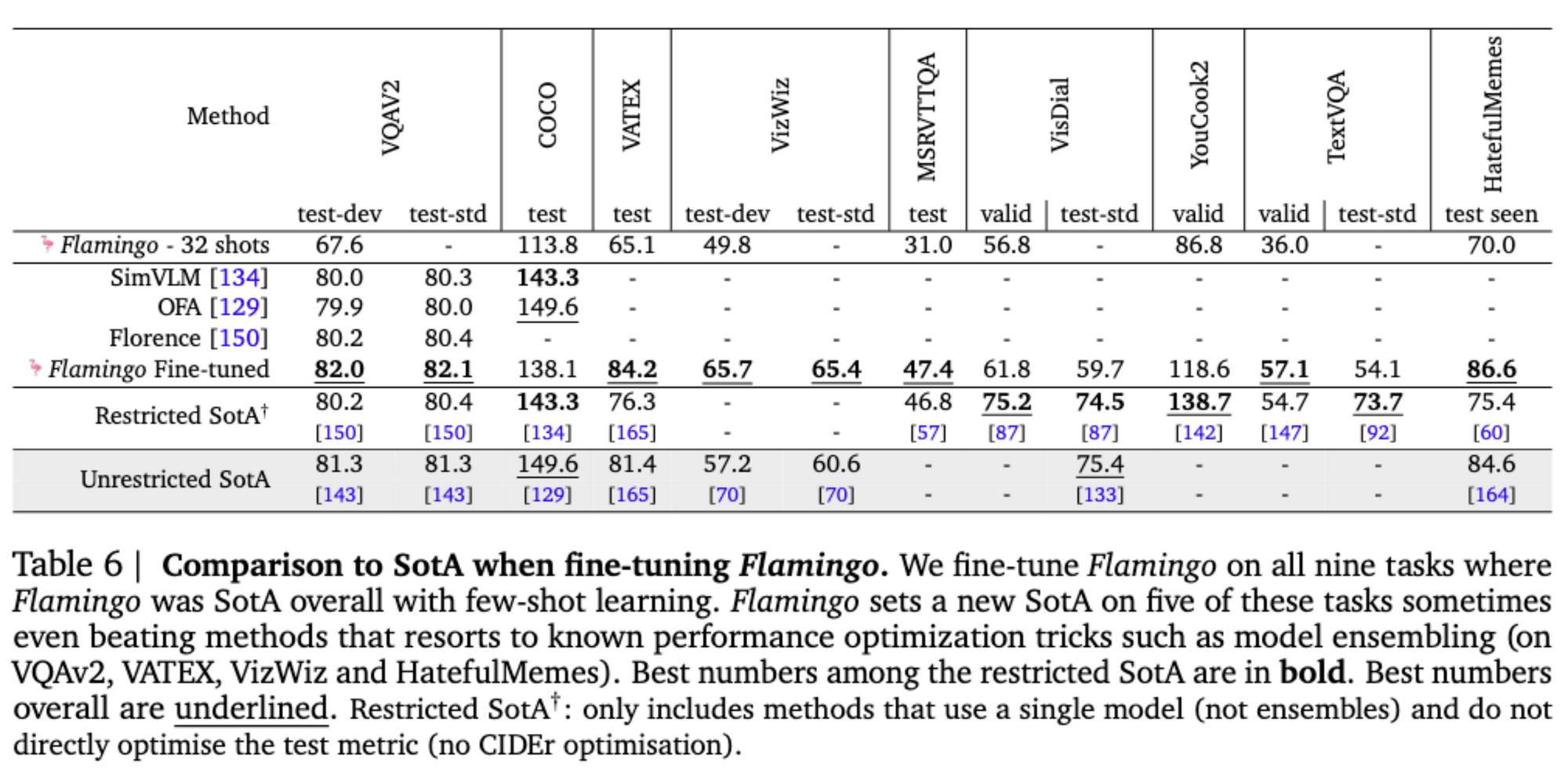
3. Flamingo sets a new state of the art in few-shot learning on a wide array of 16 multimodal language and image/video understanding tasks. In 6 out of these 16 tasks, Flamingo also outperforms the fine-tuned state of the art, despite using only 32 task-specific examples which is around 1000 times less task-specific training data than current state-of-the-art. With a larger annotation budget, Flamingo can also be effectively fine-tuned to set a new state of the art on five additional challenging benchmarks: VQAv2, VATEX, VizWiz, MSRVTTQA, and HatefulMemes.
相关工作
Language modelling
• Transformers (Attention Is All You Need): improving the modelling of long-range dependencies, increasing the throughput of models and therefore the amount of data seen during training.
• 预训练方式:MLM(masked language modeling,BERT、T5), next-token prediction
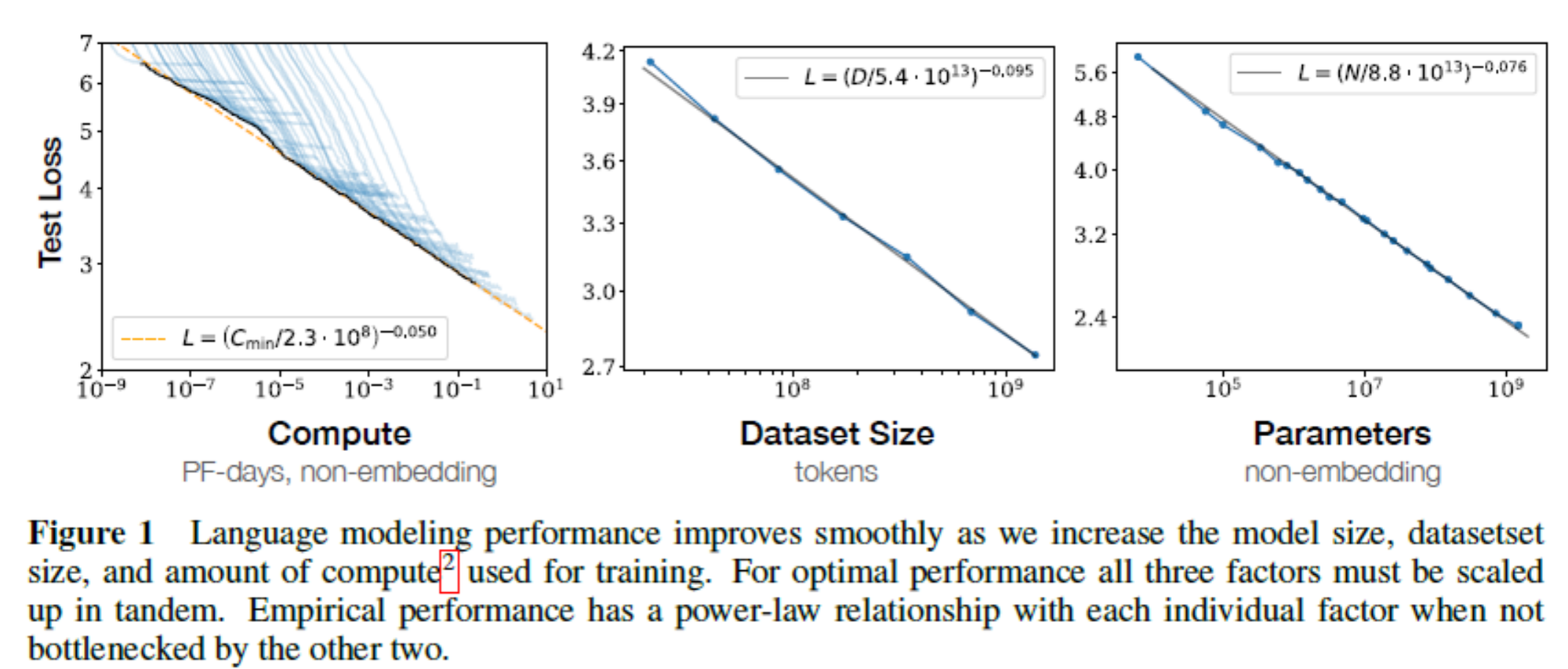
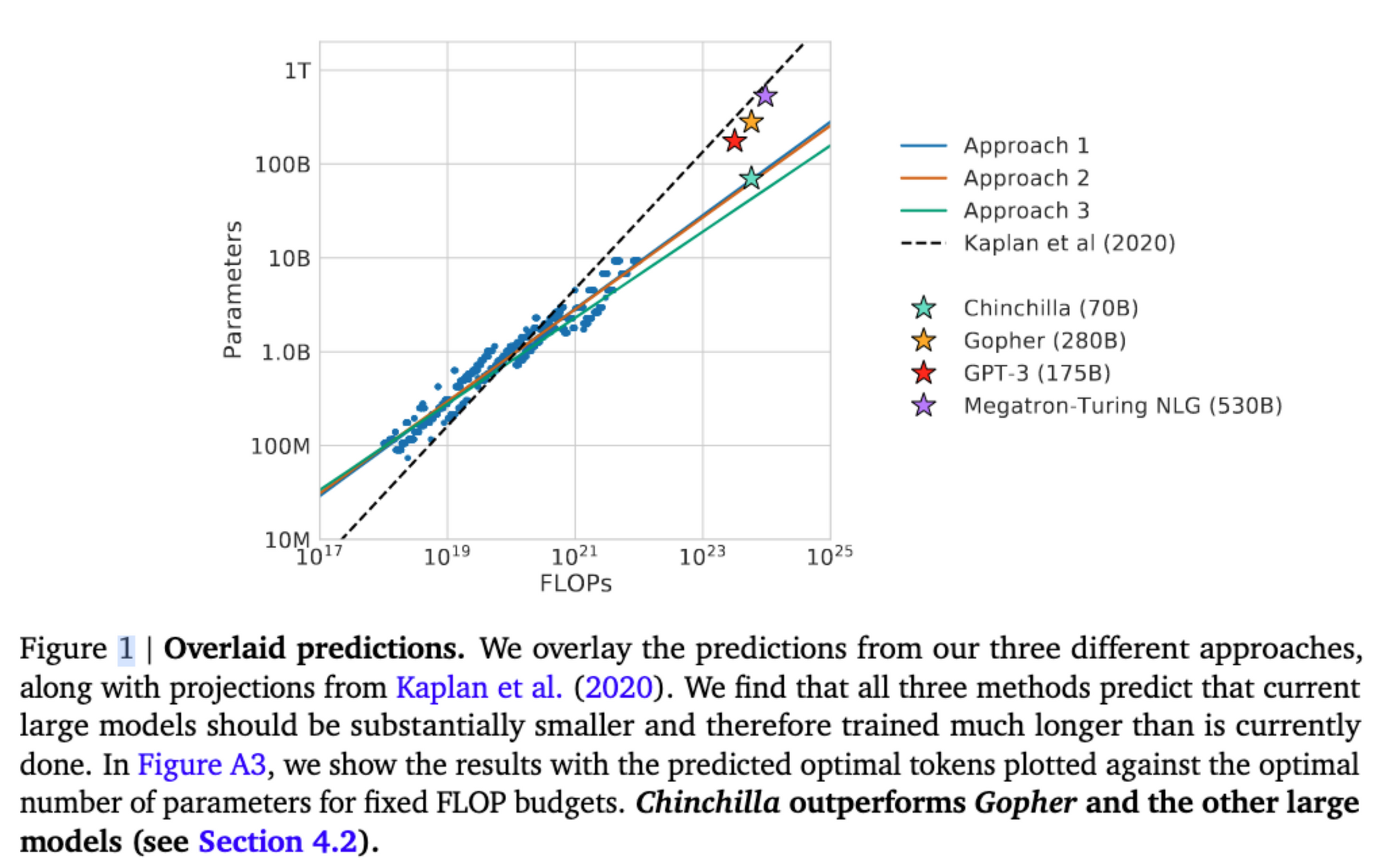
• 提升模型容量:GPT-3,Scaling Laws for Neural Language Models,Training Compute-Optimal Large Language Models(Chinchilla,number of data tokens should scale at the same rate as the model size to maximise computational efficiency.)
• 下游任务:in-context learning,例如GPT-3的用少量的(input, expected output) pair作为提示,再跟一个query input,无需额外的训练。
• 下游任务: prefix or prompt tuning,partial tuning,adapter technique
Joint vision and language modelling
• 多模态BERT方案:用detector获取visual words;VideoBERT获取视频帧的visual token;MLM loss;MRM loss;matching loss
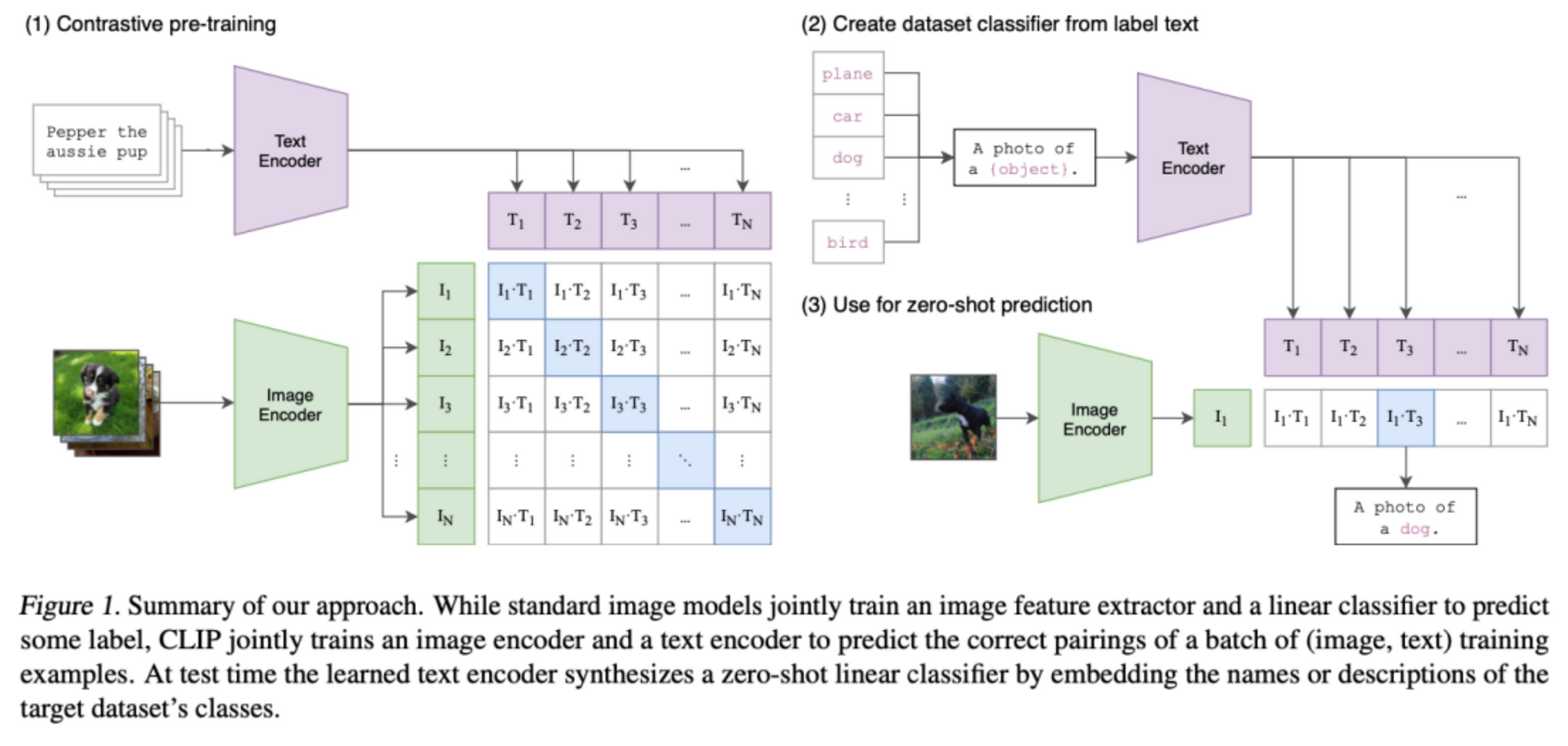
• 对比双encoder方案:以CLIP为代表,将多模态特征对齐,实现zero-shot,但few-shot性能反而下降
• Visual Language Model(VLM):能够以自回归方式生成文本,如captioning(VerTex)、HTML生成(CM3),或者将多种视觉任务(detection等)建模成语言生成任务(Pix2seq: A Language Modeling Framework for Object Detection)。如何利用预训练LM?Freezing LM(VisualGPT)、prefix tuning、adapter、CLIP+GPT3
方法
输入:language/image/video sequence(x),输出:likelihood (y) of text interleaved with x。
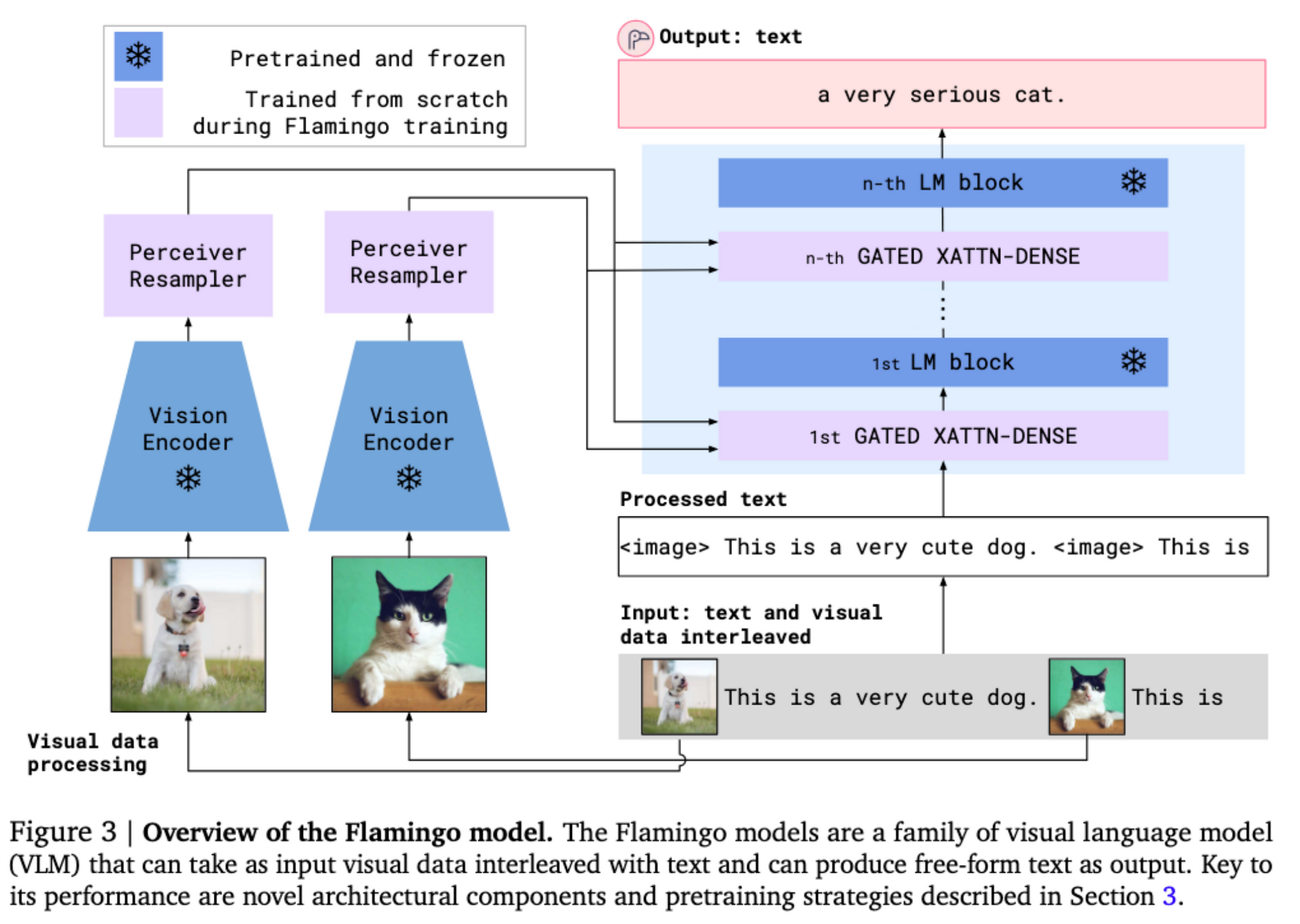
模型结构
Visual Modeling
• Vision Encoder:NFNet,在图文数据集上利用CLIP方式训练。在Flamingo训练中,对于image,生成一个pooling后的embedding,对于video,生称一个embedding序列。
• Perceiver Resampler:(Perceiver: General Perception with Iterative Attention) Unlike in DETR and Perceiver, the keys and values computed from the learnt latents are concatenated to the keys and values obtained from 𝑋𝑓.
Grated XAttn- Dense Layers
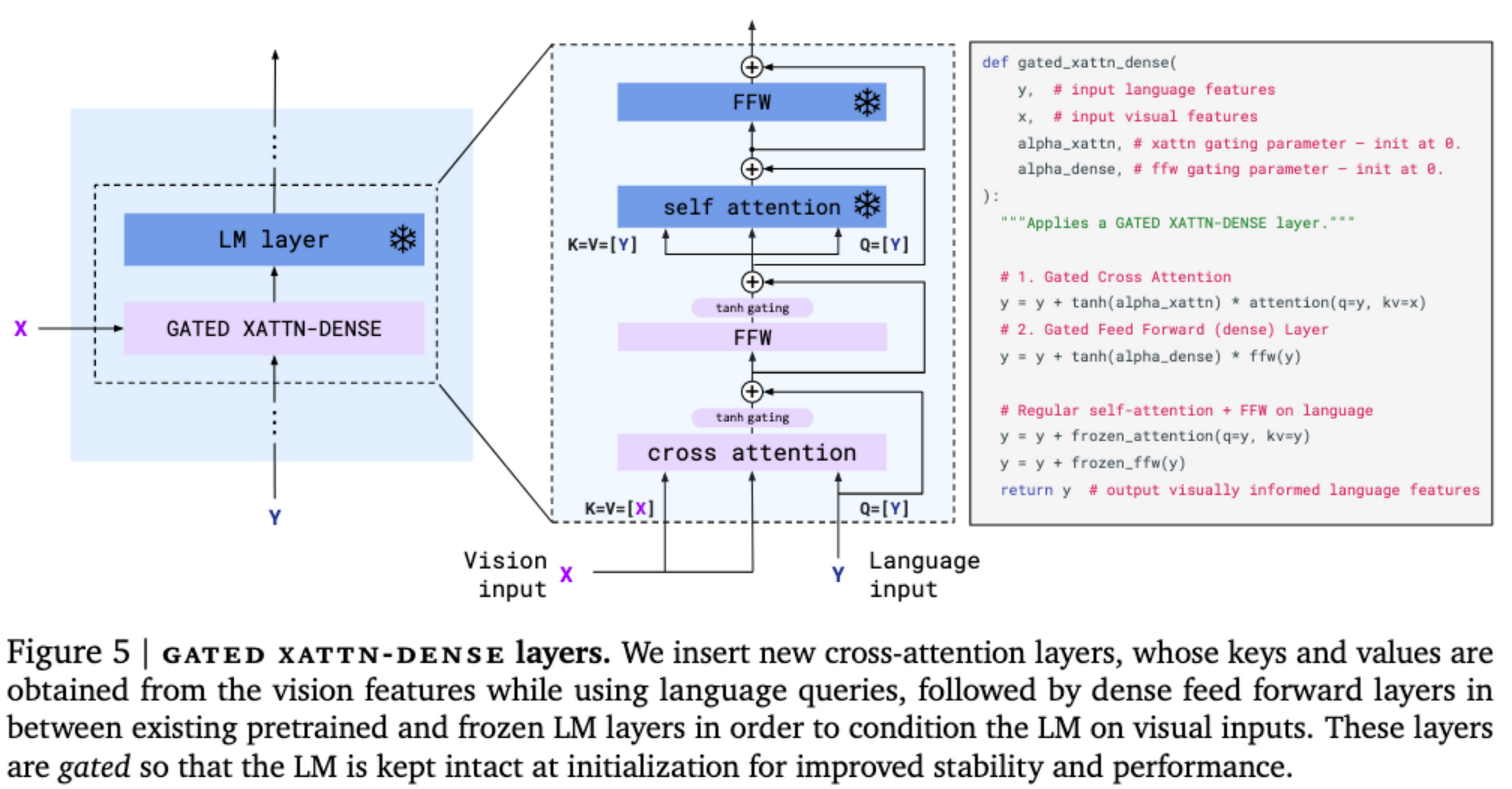
• 如何保留单模态(text only)训练的大模型知识?freeze
• 如何跨模态交互?Gated xattn-dense layer
• 如何学习?Gate初始化为0,训练中逐渐增大。 During training, the model smoothly transitions from a fully trained text-only model to a visual language model.
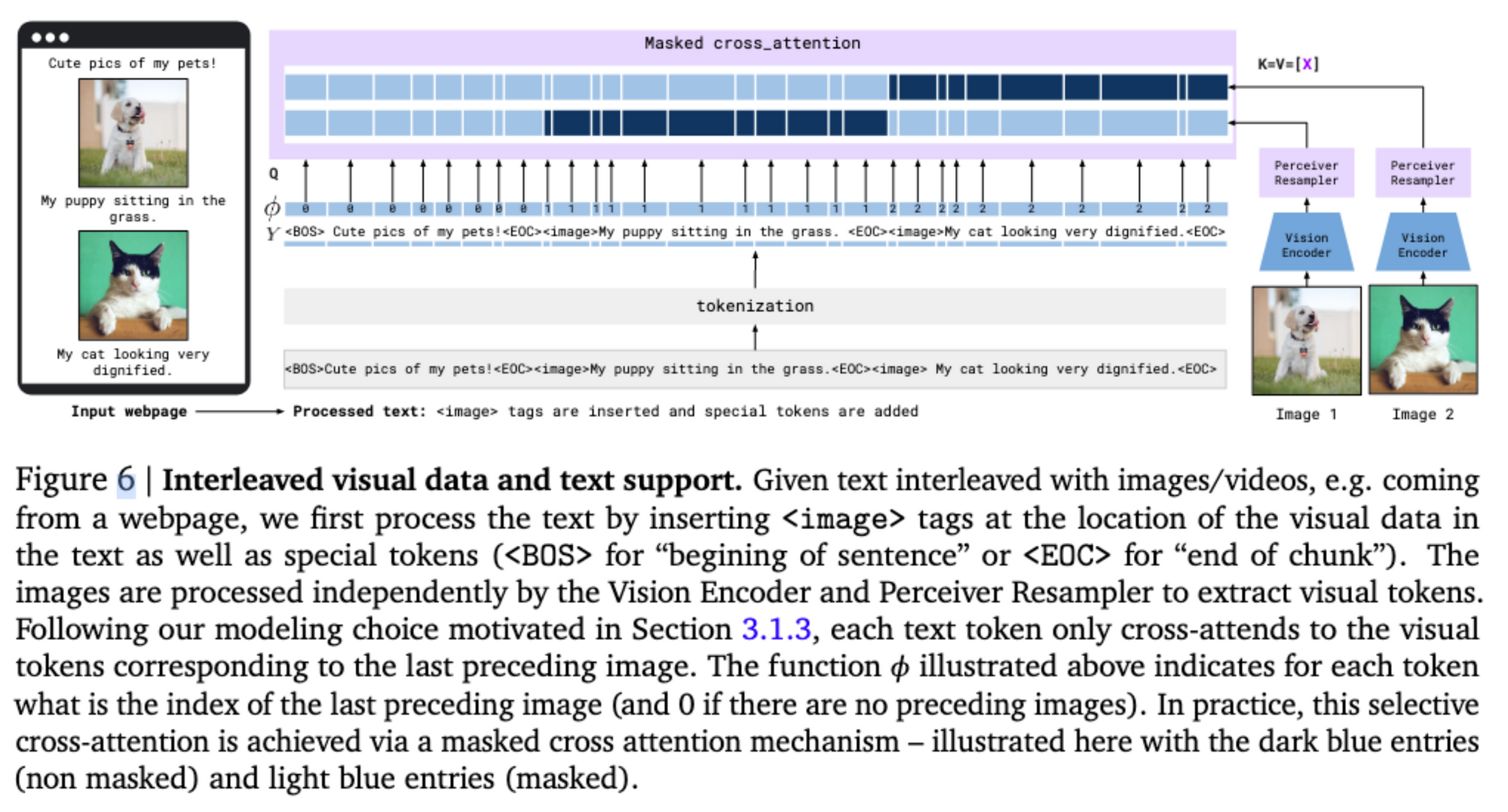
Multi-visual input support: per-image/video attention masking
训练
三种数据:image-text pairs、video-text pairs、 Interleaved image and text。

目标函数与优化策略:
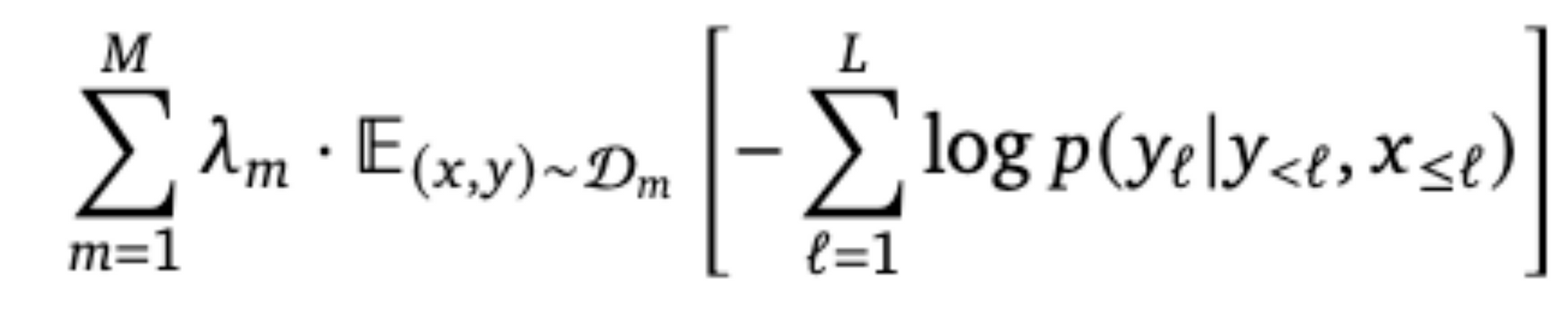
NOTE:We then accumulate the mini-batch gradients over all 𝑀 datasets before triggering an update step. We found this gradient accumulation strategy to be crucial for high performance compared to a round-robin approach.
Few-shot下游任务
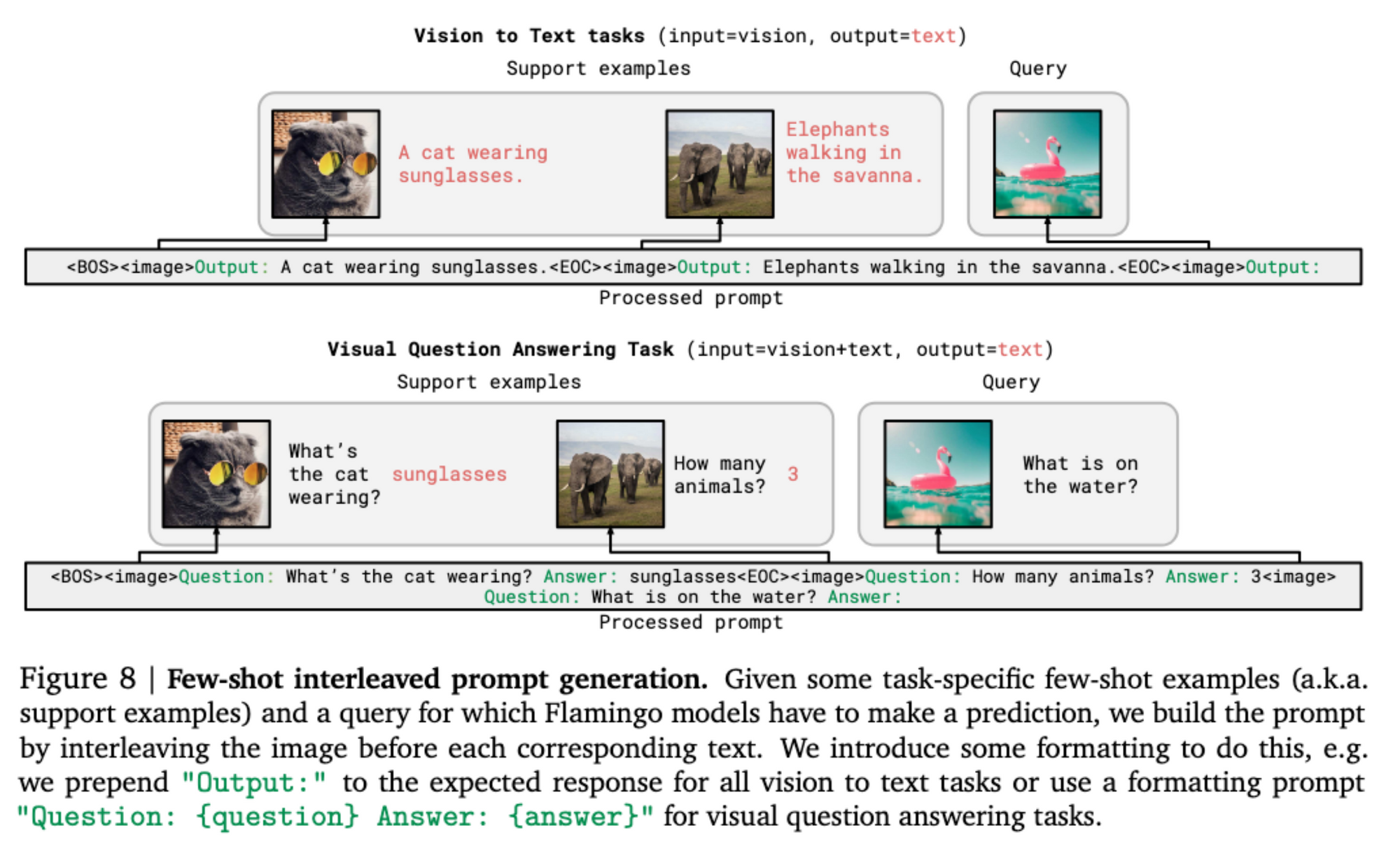
实验
• 基建和实现:16个TPUv4,JAX框架
• 代码:未开源
• 实验设计:1)多模态few-shot任务(VQA、Captioning等),和FT比较;2)close-ended任务(分类)和单模态SOTA比较;3)zero-shot image-text retrieval,和CLIP等方法比较;4)finetune Flamingo作为VL预训练模型
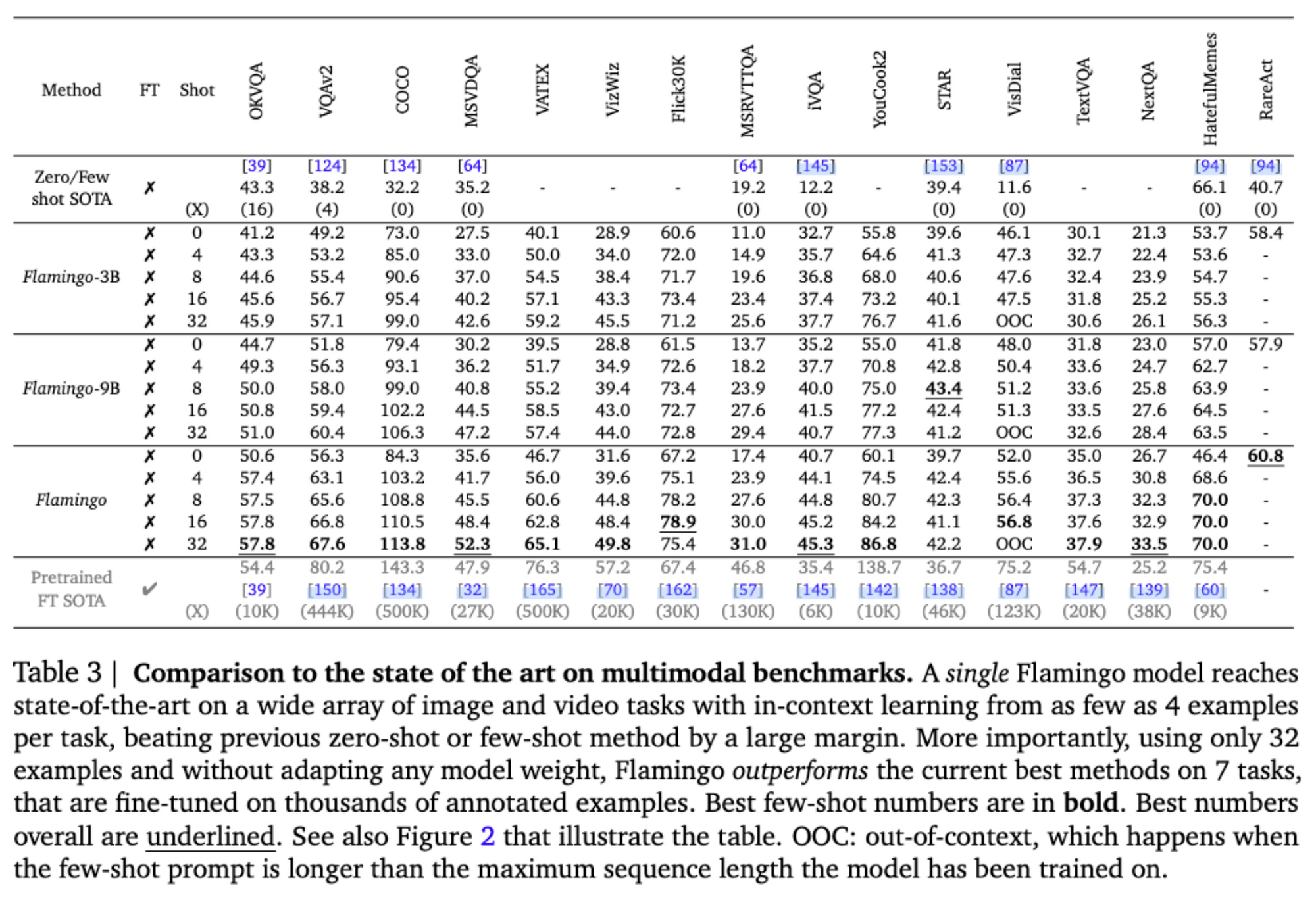
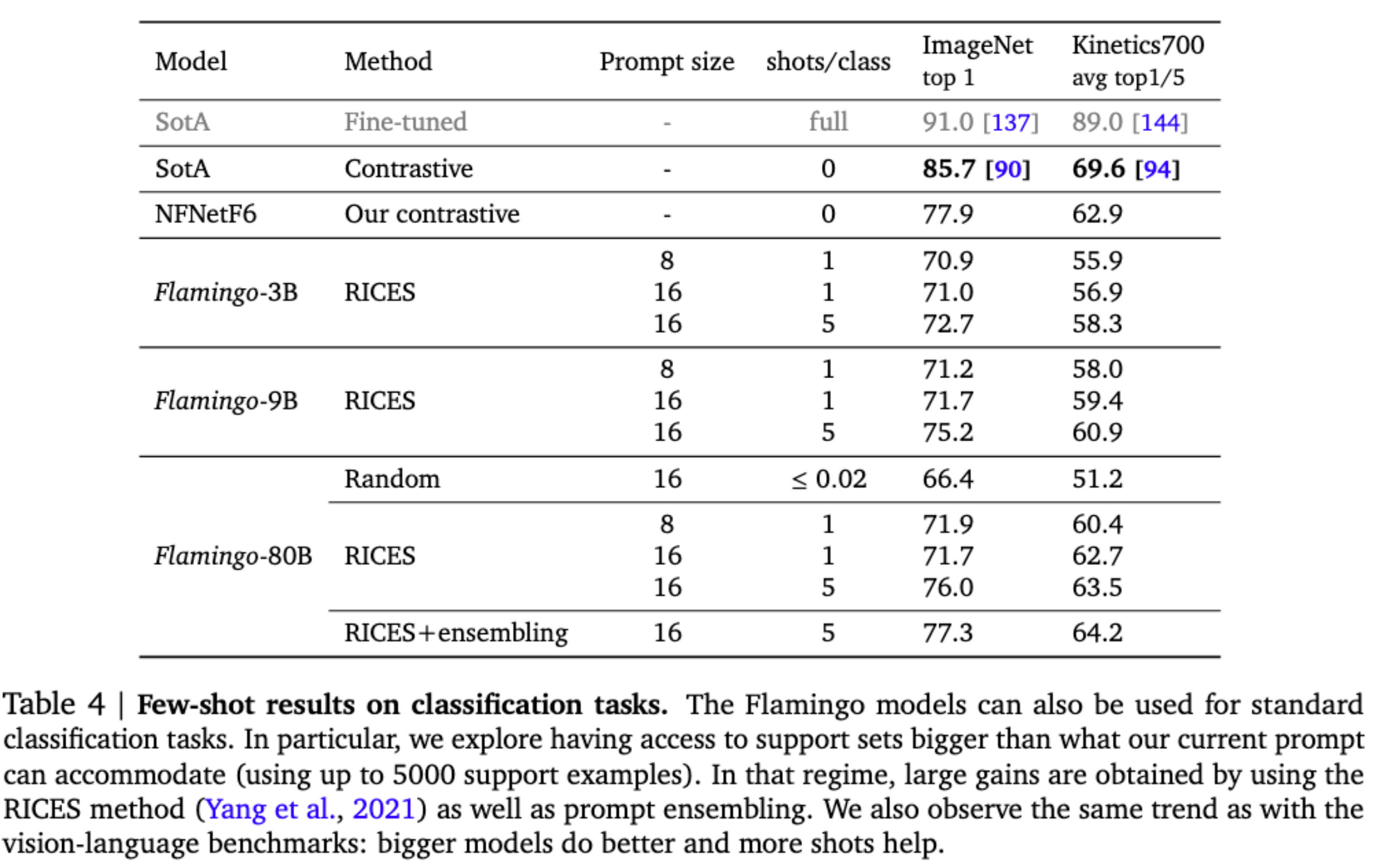
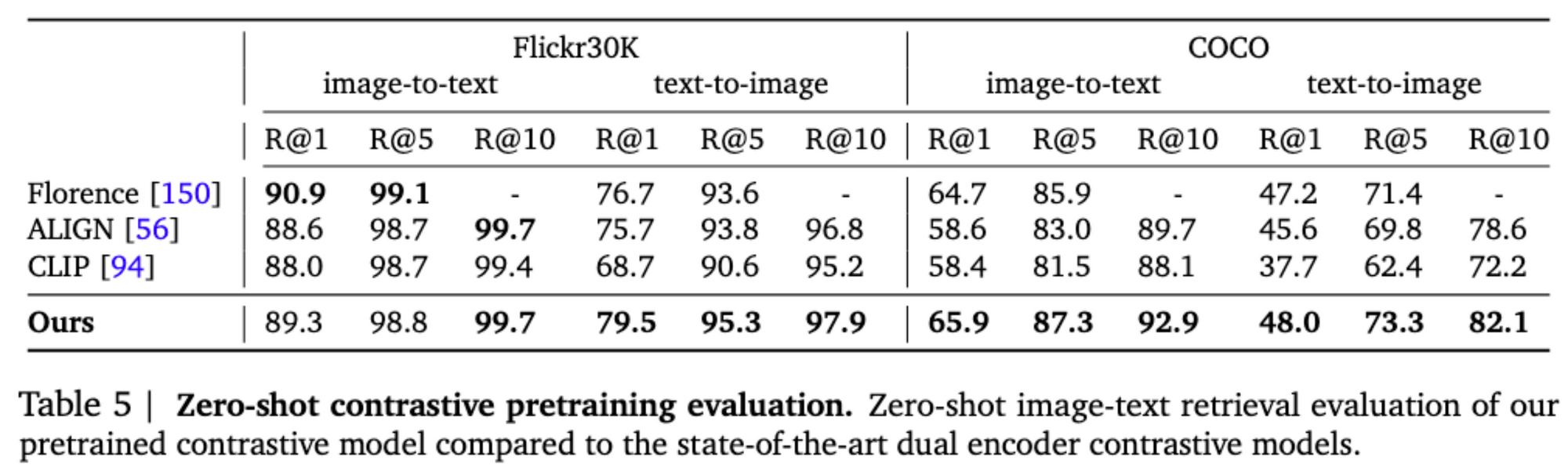
进一步工作
• 能否实现结构化/密集输出?
• In-context learning对CV的few-shot learning的启发?
• Adapter tuning方式是否是更好的利用大模型知识的方式?